Wrap-up Report
Naver Boostcamp AI Tech
P stage 3
윤준호 (T1138)
| Index | Title | Task | Date |
|---|---|---|---|
| 1 | 재활용 쓰레기 이미지 객체 탐지 | Object Detection | |
| 2 | 재활용 쓰레기 이미지 객체 영역 구분 | Semantic Segmentation |
TEAM
- 팀명: ConnectNet
- 팀원:
김종호(T1034), 김현우(T1045), 김현우(T1046) 배철환(T1086), 서준배(T1097), 윤준호(T1138)
Object detection
최종 결과
- LB: 0.4789 (mAP)
- Team rank: 5위 / 21
1 . 문제 탐색과 해결 전략
- Task 탐색 과정
- 대회 data와 함께, 관련 Kaggle reference 대회 분석을 병행하며 사전적으로 실험의 방향성을 수립 → Object detection SOTA 모델 중 task에 적합한 후보들 실험 → augmentation & loss 조합 실험 → Multi Scale 등 장시간이 걸리는 본격 모델 학습 → TTA → 앙상블(WBF) → Pseudo Labeling 시도 → 앙상블 Threshold 튜닝
- 🔍 실험 기록 노트 에 기록하면서 진행
- Data
- Augmentation
- Mosaic
- 이미지 4장을 각각 무작위로 잘라서 하나의 사진으로 만드는 augmentation. cutmix와의 차이점은 cutmix는 자른 사진이 다른 사진을 가리는 구조에 반해, 4장의 랜덤하게 자른 사진은 서로 겹치지 않는다는 점이다

- 이미지 4장을 각각 무작위로 잘라서 하나의 사진으로 만드는 augmentation. cutmix와의 차이점은 cutmix는 자른 사진이 다른 사진을 가리는 구조에 반해, 4장의 랜덤하게 자른 사진은 서로 겹치지 않는다는 점이다
- Mixup
- 배치에 있는 두 이미지를 섞는다고 할 때, 그렇지 않을때보다 무조건 object의 갯수는 크기 때문에 데이터를 여러번 보는 효과가 있다
CODE
class Mixup(BufferTransform): def __init__(self, min_buffer_size=2, p=0.5, pad_val=0): assert min_buffer_size >= 2, "Buffer size for mosaic should be at least 2!" super(Mixup, self).__init__(min_buffer_size=min_buffer_size, p=p) self.pad_val = pad_val def apply(self, results): # take four images a = self.buffer.pop() b = self.buffer.pop() # get min shape max_h = max(a["img"].shape[0], b["img"].shape[0]) max_w = max(a["img"].shape[1], b["img"].shape[1]) # cropping pipe padder = Pad(size=(max_h, max_w), pad_val=self.pad_val) # crop a, b = padder(a), padder(b) # check if cropping returns None => see above in the definition of RandomCrop if not a or not b: return results # collect all the data into result results["img"] = ((a["img"].astype(np.float32) + b["img"].astype(np.float32)) / 2).astype(a["img"].dtype) results["img_shape"] = (max_h, max_w) for key in ["gt_labels", "gt_bboxes", "gt_labels_ignore", "gt_bboxes_ignore"]: if key in results: results[key] = np.concatenate([a[key], b[key]], axis=0) return results
- 배치에 있는 두 이미지를 섞는다고 할 때, 그렇지 않을때보다 무조건 object의 갯수는 크기 때문에 데이터를 여러번 보는 효과가 있다
- Augmentation with Albumentations
- RandomCrop

- HorizontalFlip, VerticalFlip

- IAA-AdditiveGaussianNoise, GaussNoise

- MotionBlur, MedianBlur, Blur

- CLAHE, Sharpen, Emboss

- RandomBrightnessContrast, HueSaturationValue

- RandomCrop
- Add Data (Internal)
- 외부 데이터 이용은 대회 규칙 상 금지
- 마스크와 BBOX를 이용해서 원하는 오브젝트를 분리해서 다른 이미지에 붙일수 있을것이라고 생각.
- 데이터상에서 Battery, Clothes, Metal, PaperPack, Glass 오브젝트가 부족한것으로 바악해서 해당 오브젝트를 기존 이미지에 추가하는 방식으로 데이터를 증강.
- 부족하다고 판단된 오브젝트를 각 500개씩 증가시킴.
- 데이터 추가 후 기본 베이스 라인 코드로 테스트 결과 0.05정도 점수 상승해서 폴드별로 데이터 추가
- 하지만 SWIN_T에서는 마스크 부분이 새로 생성된 이미지에 존재하지 않아 적용하지 못함.
- Mosaic
- Augmentation
- Model
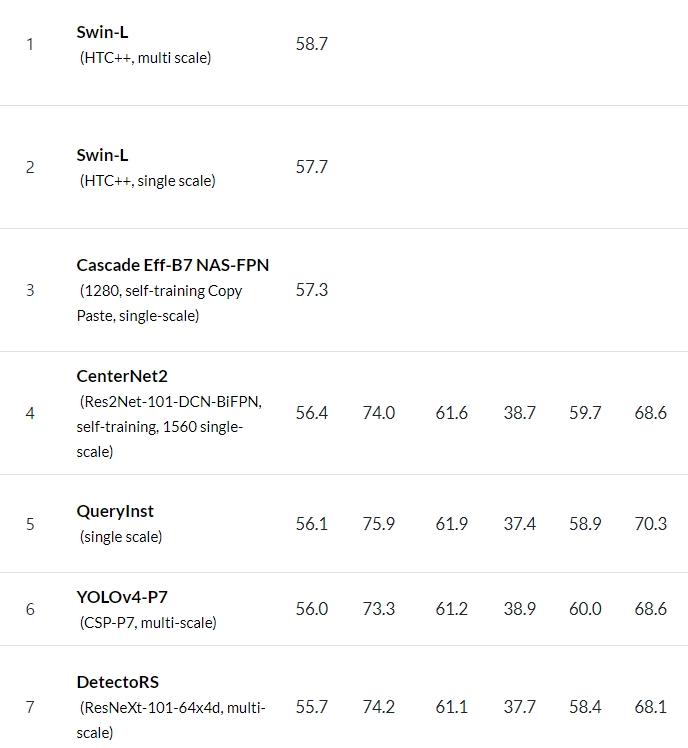
Paperswithcode 사이트를 참고해 Object Dectection의 SOTA 모델들을 선택해 테스트 진행
Screenshot
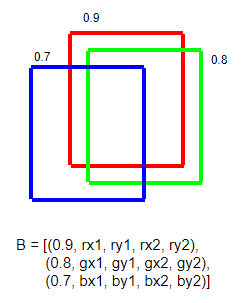
- WBF (Weighted Box Fusion) 방식으로 앙상블
WBF란?
- 여러개의 bounding box를 각각의 확률을 가중평균으로 하여 하나의 bounding box로 나타내는 방식
- Algorithms
- 각 박스를 어떤 배열 B에 확률 기준 내림차순으로 정렬한다
- 빈 배열 L과 F를 선언한다
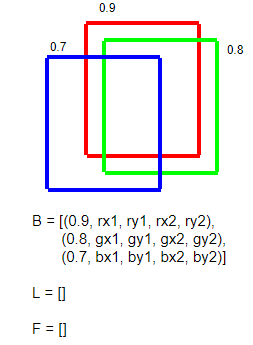
- B의 모든 원소를 순회한다
- 만일 F가 비었다면 지금 보는 원소를 F와 L에 추가한다
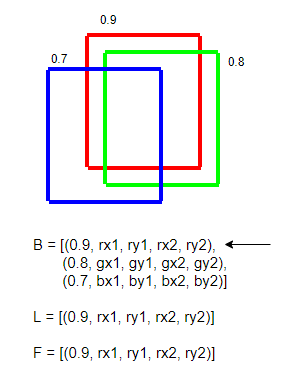
- 만일 F가 비지 않았다면 지금 보는 원소와 F의 원소 중 IOU가 특정값 (ex. 0.5)를 넘는다면 L에 지금 보는 원소를 넣고 F의 원소 순회를 중단한다
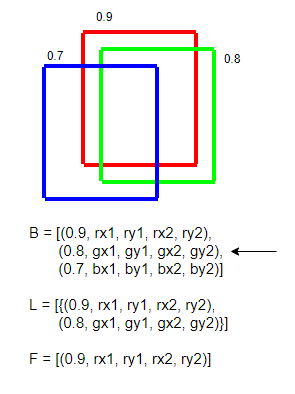
- 반복
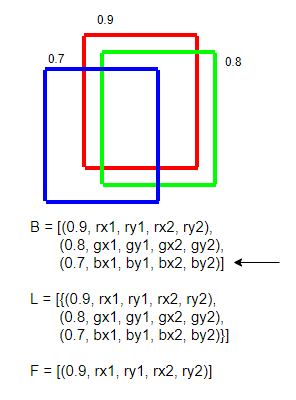
- 만일 F가 비었다면 지금 보는 원소를 F와 L에 추가한다
- 3번에 따라서 L과 F의 사이즈는 항상 같음이 보장되므로, 대응되는 위치에서의 L의 원소들로 F의 값을 갱신한다
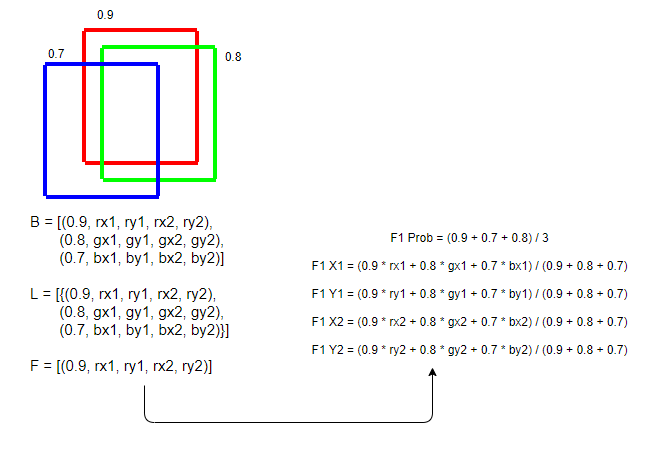
- 모든 F의 값이 갱신된 후, 전체 모델 갯수에 대한 Rescale 진행
- Rescale 식
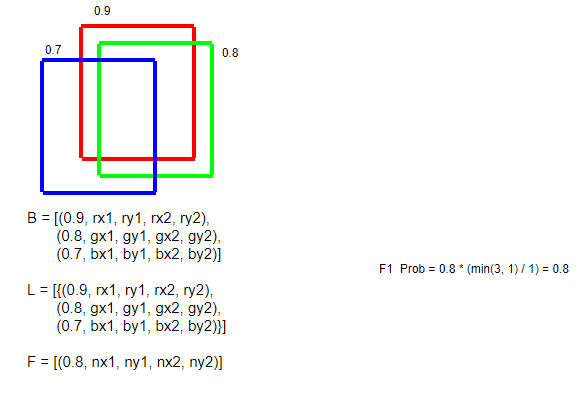
- Rescale 식
- 각 박스를 어떤 배열 B에 확률 기준 내림차순으로 정렬한다
CODE
prediction_strings = [] file_names = [] coco = COCO(cfg.data.test.ann_file) imag_ids = coco.getImgIds() img_size = 512. weights = [2, 1] # ensemble weights for model 1 and model 2 iou_thr = 0.6 skip_box_thr = 0.0001 for idx in tqdm(range(len(output1))): boxes_list1, boxes_list2, boxes_list = [], [], [] scores_list1, scores_list2, scores_list = [], [], [] labels_list1, labels_list2, labels_list = [], [], [] # model 1 for label, boxes_in_label in enumerate(output1[idx]): for box_and_score in boxes_in_label: scores_list1.append(box_and_score[4]) boxes_list1.append(box_and_score[:4] / img_size) labels_list1.append(label) # model 2 for label, boxes_in_label in enumerate(output2[idx]): for box_and_score in boxes_in_label: scores_list2.append(box_and_score[4]) boxes_list2.append(box_and_score[:4] / img_size) labels_list2.append(label) boxes_list = [boxes_list1, boxes_list2] scores_list = [scores_list1, scores_list2] labels_list = [labels_list1, labels_list2] boxes, scores, labels = weighted_boxes_fusion(boxes_list, scores_list, labels_list, weights=weights, iou_thr=iou_thr, skip_box_thr=skip_box_thr) prediction_string = '' image_info = coco.loadImgs(coco.getImgIds(imgIds=idx))[0] for i, box in enumerate(boxes): prediction_string += str(int(labels[i])) + ' ' + str(scores[i])[:11] + ' ' + str(box[0]*img_size)[:9] + ' ' + str(box[1]*img_size)[:9] + ' ' + str(box[2]*img_size)[:9] + ' ' + str(box[3]*img_size)[:9] + ' ' prediction_strings.append(prediction_string) file_names.append(image_info['file_name'])
- Pseudo-Labeling
- 기본모델 : Fold = 2 / size = 640 / EfficientDetD6
- 기본모델을 10 에폭동안 학습
→ 이 때 학습 데이터는 기본 train data과 앙상블 모델이 test data에 대해 예측한 라벨링이 되어 있는 데이터를 mixup한 데이터
- 1에서 학습한 모델을 다시 6에폭동안 학습
→ 이 때 학습 데이터는 기본 train data과 1단계 모델이 test data에 대해 예측한 라벨링이 되어 있는 데이터를 mixup한 데이터
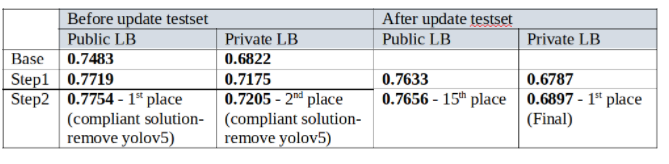
- TTA
CODE
Swin Transformer, DectectoRS test_pipeline = [ dict(type="LoadImageFromFile"), dict( type ="MultiScaleFlipAug", img_scale=[(512, 512), (768, 768)], flip=True, flip_direction=["horizontal", "vertical"], transforms=[ dict(type="Resize", keep_ratio=True), dict(type="RandomFlip"), dict(type="Normalize", **img_norm_cfg), dict(type="Pad", size_divisor=32), dict(type="ImageToTensor", keys=["img"]), dict(type="Collect", keys=["img"]), ], ), ] YOLO_V5 s = [1.33, 1.17, 1, 0.83, 0.67] # scales f = [No-Flip, LR-Flip, No-Flip, LR-Flip, No-Flip] y = [] for si, fi in zip(s, f): xi = scaled_img of test_image yi = output of scaled_img of test_image yi = descale_pred(yi, fi, si, img_size) y.append(yi) return torch.cat(y, 1) # augmented inference
- Threshold
- WBF에서의 hyperparameter
- IOU threshold : 현재 Bbox와 얼마나 유사하면 통합할 것인가를 결정하는 threshold
- Skip box threshold : 모든 Bbox의 score 중 threshold 미만의 박스는 무시
→ IOU threshold는 낮출수록 좋았으나 특정 임계값 이하로 내리면 오히려 성능이 하락
→ Skip box threshold는 낮출수록 좋았으나 파일크기가 커지는 단점이 있으며, visualization 시 지나치게 많은 박스가 존재하여 직관적으로는 납득하기 힘들었음
→ 최종적으로 IOU threshold : 0.4, Skip box threshold : 0.01로 public LB 0.5880, private LB : 0.4789 달성
- WBF에서의 hyperparameter
2. 최종 사용 모델 및 하이퍼파라미터
Models (backbone / neck / detector)
- Cascade R-CNN 계열
- ResNext101 / FPN / Cascade R-CNN
- LB: 0.4781
- optimizer : SGD (learning_rate = 0.02)
- loss: CrossEntropyLoss (Class loss), SmoothL1Loss (Bbox loss)
- hyperparameters : batch : 16, epochs : 50
- ResNet50 / RFN + SAC / Cascade R-CNN (DetectoRS)
- LB : 0.5121
- optimizer : SGD (learning_rate = 0.01)
- loss: SoftCrossEntropyLoss (Class loss), SmoothL1Loss (Bbox loss)
- hyperparameters : batch : 4, epochs : 48 or 60
- 5 fold cross-validation
- TTA 적용시 : 0.05 상승
- ResNext101 / RFN + SAC / Cascade R-CNN (DetectoRS)
- LB: 0.5247
- optimizer : SGD (learning_rate = 0.01)
- loss: SoftCrossEntropyLoss (Class loss), SmoothL1Loss (Bbox loss)
- hyperparameters : batch : 4, epochs : 48 or 60
- TTA : vertical, horizontal flip, 512, 768 resize
- ResNext101 / FPN / Cascade R-CNN
- YOLO 계열
- DarkNet / SPP / YOLO v5
- LB : 0.4916
- loss : CrossEntropy (150 epoch models), Focal Loss (240 epoch models)
- optimizer : SGD (learning_rate = 0.01)
- hyperparameters : batch : 32, epochs : 150 or 240
- 추가로 시도한 것
- TTA → 적용시 0.01 상승
- 원본 사이즈의 절반으로 Multi-scale train 진행 → 대비 모델보다는 점수 하락했으나, 앙상블 시 추가하는 것이 좋은 결과로 이끔
- WBF → TTA와 함께 적용시 0.16 상승
- DarkNet / SPP / YOLO v5
- Swin 계열
- SwinTransformer / FPN / Mask R-CNN
- LB: 0.5486
- cls_loss: LabelSmooth + CE + Focal (각 box_head 별)
- bbox_loss: SmoothL1Loss
- optimizer: AdamW (learning_rate = 0.0001)
- 추가로 시도한 것
- 첫 40 epoch은 defalut augmentation, loss를 적용하였으나, 이후 12 epoch를 재학습 시 loss 변경 + augmentation을 진행 → val mAP 0.02상승, public LB 0.06 상승
- SwinTransformer / FPN / Mask R-CNN
2.2 Augmentations
- Mixup
- RandomRotate90
- HueSaturationValue
- CLAHE
- RandomBrightnessContrast
- RGBShift
- Blur
- MotionBlur
- GaussNoise
- ShiftScaleRotate
- Multi-scale
3. 앙상블 전략
- 다양한 모델을 이용하여 모델의 다양성을 이용
- YOLO, Swin T, Cacade R-CNN
- 총 26개 모델을 WBF와 threshold 최적화를 이용하여 앙상블
- stratified kfold방식으로 데이터셋을 5개(fold0,fold1,fold2,fold3,fold4)로 나뉘어 학습하여 앙상블
- 기준(0.5이상)을 넘긴 모델 앙상블 목록
- YOLO v5
- fold0, fold1, fold2, fold3, fold4
- augment적용 fold0 ,fold1, fold2, fold3
- fold4(img size 256)
- Swin T
- fold0, fold1, fold2, fold3
- fold4(img size 768)
- Cascade R-CNN
- ResNet50
- fold0, fold1, fold2, fold3
- trainall data
- ResNet101
- fold0, fold1, fold2, fold3, fold4
- train all data
- ResNet50
- YOLO v5
4. 아쉬움이 남는 시도들
- Pseudo labeling
- 테스트 데이터셋을 inference 하면 csv 파일이 생성된다. LB 성능이 가장 좋은 결과 파일을 csv 파일을 기준으로 pseudo labeling 을 생성한다.
- BBox 성능이 0.75 이상의 값만 읽어 COCO dataset 의 파일인 pseudo.json 파일을 생성한다.
- pseudo.json 파일로 모델을 재학습시킨 모델의 성능을 올린다.
CODE
#결과 파일 읽기 df = pd.read_csv('final.csv') pred= df['PredictionString'][i] bbox = pred.split() bbox = map(float, bbox) bbox = list(bbox) bbox = numpy.array(bbox).reshape(-1,6) for d in bbox: if d[1] > 0.75: # 성능: 0.75 이상 x_min, y_min, x_max, y_max = tuple(d[2:6]) w = x_max-x_min h = y_max - y_min pseudo_annotations.append( { "id": cnt, "segmentation": 0, "area": w * h, "image_id": i, "category_id": id, "bbox": [x_min, y_min, w, h], "iscrowd": 0 } ) cnt +=1 data["images"] = pseudo_images data["annotations"] = pseudo_annotations ... #CoCo dataset 파일로 저장 with open('pseudo.json', 'w', encoding="utf-8") as make_file: json.dump(data, make_file, ensure_ascii=False, indent="\t")
→ 하루 전날 구현을 하고 성능이 좋은 무거운 모델로 테스트를 진행하여, 제 시간내에 검증을 진행하지 못하였습니다.
- EfficientDet (model)
- MMDetection 용으로 구현된 EfficientDet의 소스 코드가 있는 git repo도 있었지만, 부스트캠프에서 제공하는 서버를 사용해 학습을 진행 중이었는데 GPU의 CUDA 버전이 맞지 않아 일부 모듈과 나아가 전체 라이브러리가 동작하지 않았다. CUDA 버전 업데이트 권한을 가질 수 있었거나, 아니면 (나중에 알게 되었듯) 다른 조처럼 구글 코랩 프로를 가입해 그쪽에서 진행했다면 가능했을 텐데 아쉽다. 아니면 대회 시간이라도 좀 더 길었다면 구현해보면서 커스텀으로 맞춰볼 수도 있었을 텐데 역시 아쉽다.
Semantic Segmentation
1. 대회 전략
- 🔍 실험 기록 노트 에 기록하면서 프로젝트 진행
- Daily Mission 수행
- Augmentation & Loss 조합 실험
- Model 선정
- Skill
- TTA
- SWA
- Pseudo Labeling
- Image 생성 - 김현우T1045 진행
2. 최종 사용 모델 및 하이퍼파라미터
- efficientb3-noisy-student , FPN
- LB 점수 : 0.6248
- 모델 : decoder : FPN, backbone : efficientb3-noisy-student
- loss : Jaccard + SoftCE
- optimizer : AdamP (learning_rate = 0.0001), LookAhead
- hyperparameters : Batch size 4, Epochs : 40
- augmentation
- HorizontalFlip
- ShiftScaleRotate
- RandomBrightnessContrast
- VerticalFlip
- OneOf
- A.RandomResizedCrop(512,512,scale = (0.5,0.8),p=0.8)
- A.CropNonEmptyMaskIfExists(height=300, width=300, p=0.2),], p=0.5)
- A.Resize(256, 256)
- SWA
- se_resnext101_32x4d, FPN
- LB 점수: 0.6228 (public)
- 모델 : decoder : FPN, backbone : se_resnext101_32x4d
- loss : Jacarrd
- optimizer : Adam (learning_rate = 0.00001)
- hyperparameters : Batch size 16, Epochs : 15
- augmentation
- HorizontalFlip
- VerticalFlip
- ShiftScaleRotate
- RandomBrightnessContrast(brightness_limit=0.15, contrast_limit=0.2, p=0.5)
- RandomResizedCrop(512,512,scale = (0.5,0.8))
- efficient-b3 , FPN
- LB 점수: 0.5897 (public)
- 모델 : decoder : FPN, backbone : efficient-b3
- loss : Cross Entropy
- optimizer : AdamW (learning_rate = 0.00001)
- augmentation
- HorizontalFlip
- ShiftScaleRotate
- RandomBrightnessContrast
- RandomResizedCrop
- OpticalDistortion
- VerticalFlip
- pseudo hyperparameters : batch 8, epochs 20
- pseudo 학습: Fold로 나뉜 모델, 각각 psudo labeling 학습 진행
3. Loss 실험
동일한 모델을 사용하여, Loss 값에 따른 Score 실험
- Decoder : deeplabV3+
- Backbone : efficientb3-noisy-student
- Optimizer : AdamW

4. Augmentation 실험
- 데이터에 적용 가능한 Augmentation 자세한 내용

- 사진을 어떻게 자를 것인가? 자세한 내용

Scale58 = RandomResizedCrop(512,512,scale = (0.5,0.8))
Scale68 =RandomResizedCrop(512,512,scale = (0.6,0.8))
Scale46 = RandomResizedCrop(512,512,scale = (0.4,0.6))
Scale24 = RandomResizedCrop(512,512,scale = (0.2,0.4))
5. 아쉬움이 남는 시도들
- Unet, Unet ++, Unet3+을도 학습해 앙상블에 추가하려고 했으나 성능이 나오지 않아 제외함
- pseudo labeling
- 학습 방법
- label이 없는 데이터셋(test셋)에 대해 매 배치마다 생성 및 학습
- 50batch마다 기존 train셋을 1epoch학습 진행
for each_test_image in test_loader: model.eval() output = output of model with each_test_image oms = output label model.train() unlabled_loss = alpha_wight * CE(output,oms) if batch % 50 == 0: for each_train_image in train_loader: train_output = output of model with each_train_image→ 그러나, CE(output, mos)는 사실상 같은 값이기 때문에 값이 0에 수렴하여 의미가 없음. 따라서, 위 pseudo code는 원래의 pseudo-labeling의 의도와는 조금 다른 방식으로 작동함. 그럼에도 불구하고 적용하지 않았을 때 보다 0.06이 상승하는 효과가 있었는데, 이는 단순히 내부 for문에 의해 train이 추가적으로 이루어진 결과에 기인한다고 생각함. 또한, 학습된 모델로 pseudo 레이블을 생성할 때 confidence가 일정 수준 (0.75 등) 이상인 픽셀만 한정하는 threshold를 주는 방법이 더 general한 성능 향상을 보이는 걸로 (대회 종류 후에) 파악함.
- 학습 방법
6. 보완할 점
- Library 버전 통일하기
- EDA를 통해서 이미지 특성에 따라 실험하기
- 프로젝트 진행 단계별로 다양한 시각화를 도입하기
- 학습 진행 시 ,다른 작업을 못할 때는 SOTA 모델 TTA나 CRF 같이 테크닉 탐색
- loss를 조합 시, 특정 모델에서만 좋았던 것일 수도 있으니 참고하기
- 최대한 작은 모델로 실험 하기 -> 기본적 조합 (loss, optim, augmentation, batch_size, lr, epoch)
- 기준 점수 (ex. 현재 single SOTA 점수의 +- 15%)를 충족하지 못하면 과감하게 드랍하기
- csv 파일로 soft voting, hard voting 앙상블 기능을 미리 구현
- 개인별 앙상블 미리 LB 점수 체크하면서 실험
- 낮에는 작은 모델로 기능 테스트를 진행하고, 밤에는 성능이 좋은 모델로 실험을 진행함 -> 성능이 좋은 모델은 모두 다른 조합으로 진행함
- pseudo labeling 다른팀과 비교해서 검증 및 재사용
- 목표를 세분화해서 각각 데드라인을 지정
- 항상 모델 pt 저장해서 필요할 때 사용하기
→ 이 보완할 점들이 두 번째 프로젝트인 object detection 대회에서는 상당 부분 반영되어, 성과를 올리는 데 큰 도움이 됨
전체 프로젝트 회고 및 느낀점
잘한점
- Segmentation 대회에서 아쉬웠던 점들을 보완해 object detection 대회에서는 효율적으로 팀을 운영하고 프로젝트를 진행
- Task의 문제 상황을 탐색해 인식하고, 그것을 해결하는 데에 집중함
- Small object에 대한 detection 점수가 낮게 나오는 (recall 계산에 의해 전체 점수도 낮아지는) 문제를 multi-scale을 활용해 극복
- Imbalanced data를 파악하고, 부족한 클래스의 이미지를 중심적으로 cutmix 등의 아이디어를 활용해 (mask 정보를 이용해 배경을 제외한 물체만 가져와 다른 사진 배경에 추가) 추가적으로 생성하는 것을 구현해 overfit 문제를 해결하고 mAP를 향상시킴
- 대회 종료 직전까지 최적화 등의 새로운 시도를 멈추지 않음
아쉬운 점
- Segmentation 대회에 성능 향상에 큰 도움이 되었던 pseudo labelling을 object detection에서는 성능 향상에 실패해 앙상블에서 제외됨
- 대회 1~2일차에 SOTA 구현을 완성하지 못하고 지체되어 다른 실험들의 시기에도 영향을 미친 점
- Swin 모델 계열에는 새로 생성한 데이터를 활용할 수 없었던 점 (swin 모델이 학습에 추가적으로 이용하는 mask를 json에 새로 추가해줘야하는 것을 늦게 알아차림)
- 앙상블 하기 전에 파일형식, 앙상블 방식을 미리 합의해서 진행하면 시간 효율적이었을 것 같음
- val score와 public LB의 관계를 좀 더 명확히 파악하는 실험을 했으면 좋았을 것 같음
개선할 점
- MMdetection Config, model , neck 다시 확인하고 정리해보기
- custom model 구현 시도
- 학습 모델 결과를 EDA 하여 클래스의 문제인지, Bbox 의 문제인지 확인할 것
- 모델간 상관관계도 EDA 하여 앙상블에 효과적인지 미리 판단할 것
- 논문도 같이 리뷰하면서 대회를 진행할 것
- Validation 전략을 짜면서 계획하면서 실험할 것
- 문제를 정의하고 해결하려는 과정에 대해 좀더 정리되고 체계적으로 진행할 것
- 실험과정 정리
- custom model을 구현해 본다.
느낀 점
- 마지막 리더보드에 너무 신경을쓰다보니 대회의 순위에만 집중한거 같다. 좀더 테스크에 대한 문제점을 체계적으로 파악하고, 해당하는 문제점에 대한 해결책을 찾아내는 방식으로 진행하는 연습이 필요할 것 같다. 그래도 같은 팀으로 두 번 프로젝트를 했는데, 첫 번째보다 두 번째에는 훨씬 체계적으로 프로젝트를 진행해서 결과적으로도 높은 순위를 쟁취했기에 매우 기쁘다.