Wrap-up Report
Naver Boostcamp AI Tech
P stage
윤준호 (T1138)
| Title | Task | Date |
|---|---|---|
| 수식 인식기 | NLPOptical Character Recognition |
최종 결과 : 0.5639 (팀 순위 7위)
<기술적인 도전>
1 . 전략
1.1 Task 분석과 접근법 도출
- 유사한 task인 Scene Text Recognition을 참조하여 SOTA 논문 분석 및 리뷰
- 동일한 task인 논문을 참고해 베이스라인 아키텍처 수정 방향 논의
1.2 다양한 실험을 통해 성능 향상 시도
- 하이퍼파라미터 튜닝
- SATRN의 hidden dimension, filter dimension증가
- 0.01의 성능 향상
- SATRN의 hidden dimension, filter dimension증가
- 모델 앙상블
- Penalty 추가
- \frac{1}} 처럼 괄호가 맞지 않지 않는 경우가 발생
- 그러나, 이미 토큰단위에서 loss를 계산하기 때문에 2차적으로 stack을 이용해 1 - (짝이 맞는 괄호 쌍 / 전체 괄호 쌍)을 더해줌으로서 일종의 penalty 부여
- 데이터셋 추가
- Aida Dataset을 추가적으로 학습(100000+100000)
- 더 데이터를 추가하려했으나 서버용량 때문에 추가못함 10만개 == 약 12GB
- 학습 시간이 오래 걸림
- Data Augmentation
- Image Binarization💡데이터의 noise가 매우 심하여 최대한 숫자와 배경만 남기는 Adaptive Threshold를 통해 노이즈를 감소
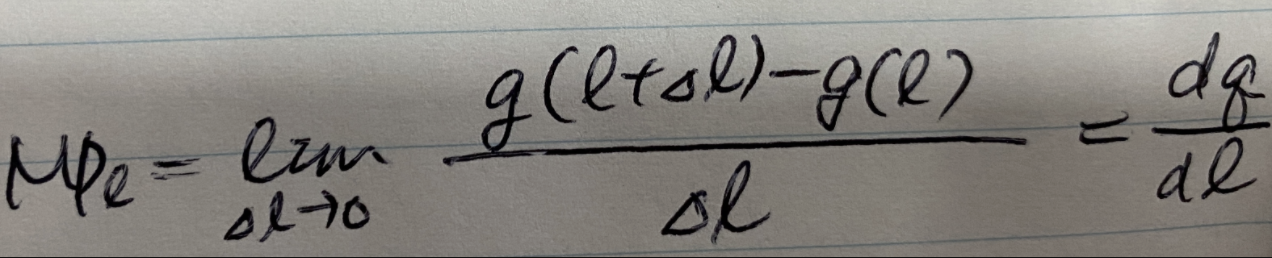
Original

Binarization
- Random Rotation / Affine(Shear)💡다양한 각도에서 촬영된 다양한 필체로 쓰인 손글씨 데이터를 잘 아우르는 분포를 학습할 수 있도록 다양한 변환을 적용
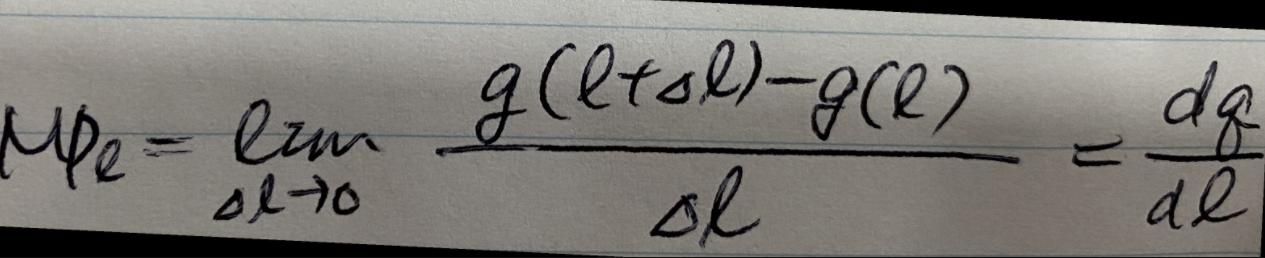
Rotation
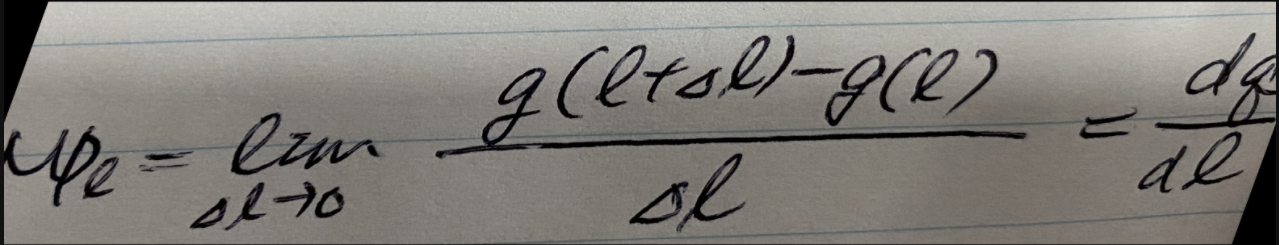
Shear
- ColorJitter (Bright / Contrast)
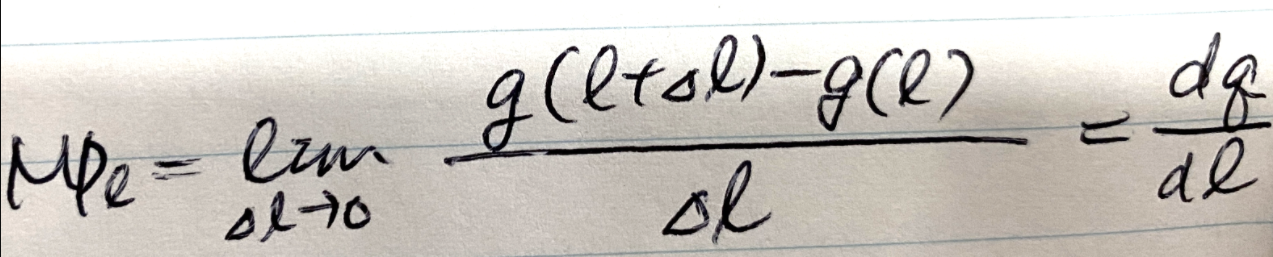
Random Brightness
Random Contrast
- Image Binarization
- Outlier Correction

- 가로/세로 가 0.75 보다 작은 경우 이미지의 내부의 글자가 세로로 출력되어 있음
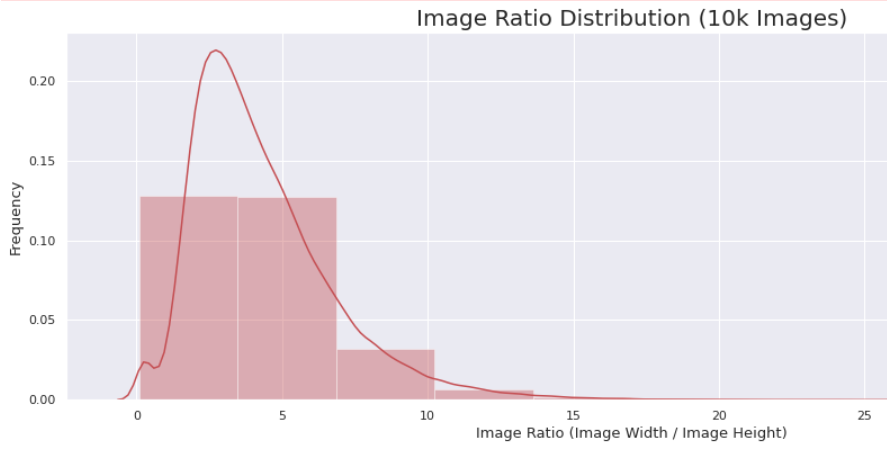
- 데이터의 종횡비 (가로 / 세로)가 0.75이하인 경우, 즉 세로가 지나치게 긴 이미지들은 일괄적으로 시계방향 90도 회전 → 0.051 상승
- ex) 종횡비가 0.75 이상, 0.8이하인 데이터

- ex) 종횡비가 0.75 이상, 0.8이하인 데이터
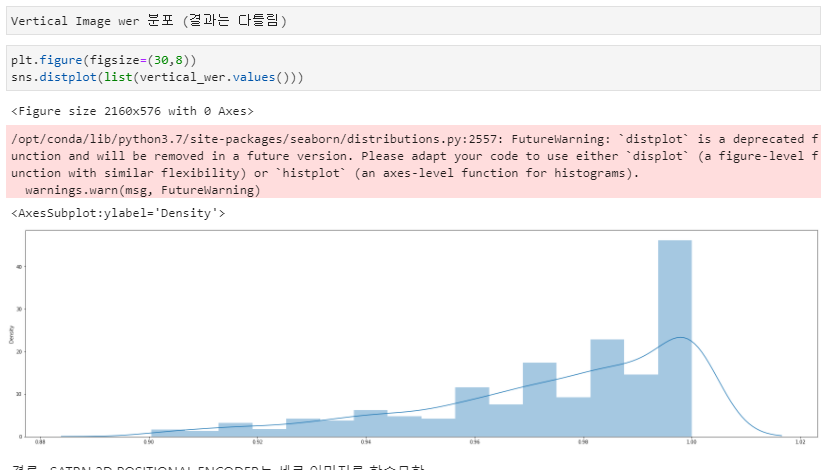
- Vertical Image는 못맞추는걸로...
- Model
Paperswithcode 사이트를 참고해 Scene Text Recognition의 SOTA 모델들을 선택해 테스트 진행
ScreenShot

2. 모델 아키텍처 (backbone / encoder / decoder)
1) SATRN
- DenseNet / Transformer (encoder + decoder)
- LB: 0.7888
- optimizer : Adam (learning_rate = 5e-4)
- loss: CrossEntropyLoss
- hyperparameters : batch : 16, epochs : 50
- image_size: (128, 256)
- 추가로 시도한 것
- Dense layer depth 증가
- 다양한 Augmentation 적용
- positionalencoding2D 을 adaptive2DpositionEncoder로 개선
- hidden dimension, filter dimension 증가
2) Aster
- CNN / Bi-LSTM / LSTM
- LB : 0.7917
- loss : CrossEntropy
- optimizer : Adam (learning_rate = 5e-4)
- hyperparameters : batch : 32, epochs : 50
- image_size: (80, 320)
- 추가로 시도한 것
- Deformable conv layer
주어진 데이터셋에는 기울어진 수식들이 많이 들어있었음.
기존의 논문에서는 STN을 통과하여 이미지를 정렬시킴 → 연산량이 많다
마지막 3 block에서 conv layer를 Deformable conv layer로 바꾸어 성능 향상을 봄.
- Deformable conv layer
3) CSTR
- Naive CNN / CBAM & SADM / Multiple Linear
- LB : None
- Valid Acc : 0.28 ~ 0.31
- optimizer : AdaDelta (learning_rate = 0.0 ~ 1.0 CosineAnnealingWarmUp)
- loss : LabelSmooth (ratio = 0.1)
- hyperparameter : batch 100, epochs : 50
- image_size : (48, 192)
- 추가로 시도한 것
- 실험초반 오버피팅 이슈 발생 → dropout(p = 0.1), weight_decay (1e-3) 설정
- 이후 오버피팅은 일어나지 않았으나 성능 이슈 발생
- CNN Layer의 dim을 2배씩 늘려 전체적 파라미터를 2배로 size up → 실패
3. 앙상블
- 서로 다른 방향성을 가진 transformer기반의 Satrn과 attention기반 모델을 앙상블
- SATRN, Attention
- 멀티스케일 러닝의 효과를 보기위하 각 모델마다 다른 크기의 이미지입력을 사용
- 서로 다른 seed를 이용하여 서로 다른 train셋으로 학습하는 효과를 이용
- 앙상블1 : SATRN(128,384), SATRN(128,256), Aster(80, 320)
- 싱글 모델 보다 성능이 떨어짐 (LB : 0.74)
- 128, 128 이미지로 동일하게 inference 하여 성능이 떨어졌음
- 앙상블1 의 문제점을 보완하기 위해 앙상블 2를 시도
- 앙상블2 : SATRN(128,384), SATRN(128,256), Aster(80, 320) (TTA적용)
- 입력 이미지를 학습시 입력한 이미지 크기에 맞게 inference
- 메모리 폭파 → with torch.no_grad() 넣지 않아 발생한 문제
- 앙상블3 : SATRN (128, 256) + Aster(80, 320)
- 서버 문제 때문에 LB 점수를 알 수 없음
4. 시도했으나 잘 되지 않았던 것들
- 앙상블
- 제출방식에 있어 기존방식과 달라 예외를 완벽히 잡지 못함
- 앙상블 1은 모델의 성능이 하락
- 앙상블2와 앙상블3은 부스트캠프의 서버의 용량문제로 성능 측정 불가
- 새로운 모델 구현
- SRN, CSTR 구현 시도
- Efficientnetv2 FPN Backbone 구현 시도
- 기존 Attention 베이스라인에서 GRU 에러 fix 후 구현 → LSTM과 큰 차이 없음
- Beam search
- RNN, LSTM에 있어 각각 token 단위에서 예측하는 걸 보완해 top k개의 후보를 고려하는 알고리즘인데, 모든 word가 한 번에 입력되고 예측하는 transformer의 경우 성능 향상에 도움이 될지 미지수임
- 같은 이유로 RNN, LSTM에서와 달리 transformer에서는 token 선택 시 사전 확률 - 사후 확률이 달라지기 때문에 구현 난이도가 상당하고, 한다고 하더라도 연산량이 큰 폭으로 증가함
- 시각화
- attention map을 시각화 하려했지만 못함
- 데이터셋 추가
- Aida dataset을 추가하여 하였으나 점수가 별로 안올라서 포기
- Im2Latex를 추가하려고 하였으나 서버용량이 부족하여 추가하지 못함
<프로젝트 회고>
유사한 테스크의 논문들을 탐색하며, 주어진 베이스라인에서 벗어나 새로운 모델들을 많이 시도해봤다는 점에서 뿌듯한 프로젝트였다. 하지만 결과적으로 가장 좋은 성능이 나온 모델은 베이스라인인 SATRN 아키텍처를 수정한 것이었고, 우리 팀은 (실패한) "모델의 탄생과 죽음"이라는 제목의 발표를 제작하게 되었다. 비록 성능 향상에 영향을 주진 못했지만, 문제를 인식하고 새로운 접근들을 시도한 후 실패한 원인을 분석하면서 많이 성장할 수 있었기 때문이다.
이번 프로젝트로부터 얻은 가장 큰 교훈은, 아주 유사해보이는 테스크일지라도 SOTA로 검증된 레퍼런스 모델을 가져다 쓸 때는 그 궁합을 철저하게 분석해야한다는 것이다. 텍스트 multi-line recognition에서 아주 좋은 성능을 보이는 CSTR을 구현하고 수식 데이터셋에 적용했지만 성능은 별로 좋지 않았다. 기존 CSTR의 경우 알파벳과 숫자로 37개의 토큰과 25의 문장 최대 길이로 학습되고 예측에 사용된 반면, 수식 데이터셋에는 무려 245개의 토큰과 254의 문장 최대 길이로 학습되고 예측했기 때문에, NLP transformer가 아닌 CNN으로 토큰을 예측하는 CSTR의 모델이 각각 7배, 10 배에 달하는 토큰, 문장 최대 길이의 복잡도를 따라가지 못하고 underfit이 발생한 것으로 해석된다. 대회 성적은 중위권이지만, 성공과 실패를 통해 성장한 지표로는 1등이 아니었나 생각한다.